0
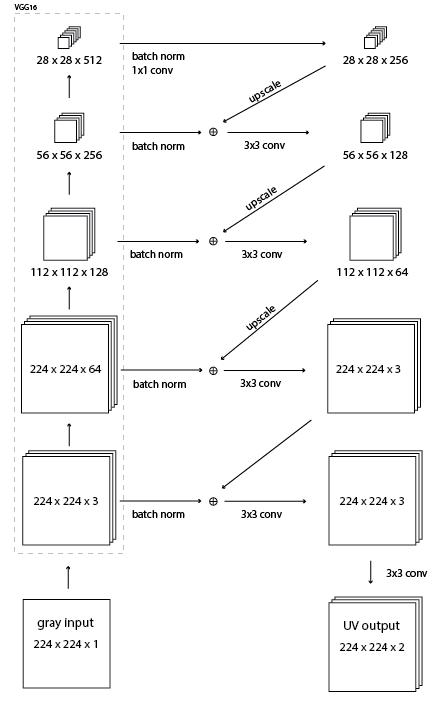
this imageのモデルを作成しようとしています。関連するコードは次のとおりです。ケラスで入出力する画像
{kind=link}
base_model = VGG16(weights='imagenet')
conv4_3, conv3_3, conv2_2, conv1_2 = base_model.get_layer('block4_conv3').output,
base_model.get_layer('block3_conv3').output,
base_model.get_layer('block2_conv2').output,
base_model.get_layer('block1_conv2').output
# Use the output of the layers of VGG16 on x in the model
conv1 = Convolution2D(256, 1, 1, border_mode='same')(BatchNormalization()(conv4_3))
conv1_scaled = resize(conv1, 56)
.
.
.
conv5 = Convolution2D(3, 3, 3, border_mode='same')(merge([ip_img, conv4], mode='sum'))
op = Convolution2D(2, 3, 3, border_mode='same')(conv5)
for layer in base_model.layers:
layer.trainable = False
model = Model(input=base_model.input, output=op)
model.compile(optimizer='sgd', loss=custom_loss_fn)
私はディレクトリに色付きの画像がたくさんあります。入力画像は、画像のグレースケール(224x224x3)で、opは、YUV画像を得るためにグレースケール(224x224x1)に追加できる画像(224x224x2)のUVプレーンでなければなりません。カスタム損失機能は、元の画像のUVと予測のUVに作用します。
私はどのようにトレーニングしますか?