1
私は次の用語を理解したい:私はこれまで理解することは、スパークマスターであるハーフープ(シングルおよびマルチ)ノード、spark-masterおよびspark-workerとは何ですか?
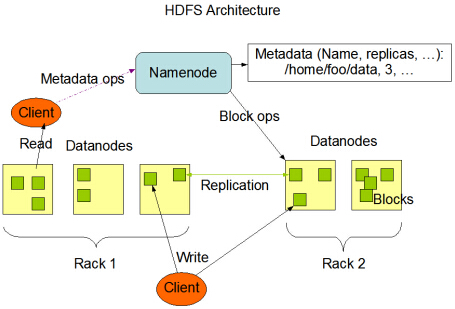
Hadoopの(単一ノードおよびマルチノード) スパークマスター スパークワーカー 名前ノード データノード
がジョブエグゼキュータですすべてのスパーク作業員を処理します。 hadoopはhdfs(私たちのデータが格納されている場所)であり、spark作業者が与えられた仕事に賛成するデータを読み込む場所です。私が間違っていれば私を修正してください。
また、namenodeとdatanodeの役割を理解したいと思います。私はnamenodeの役割を知っています(すべてのデータノードのメタデータ情報を持っていますが、それは1つだけ(好ましい)でなければなりませんが、2つになる可能性があります)、データノードは複数あり、
datanodesは同じhadoopノードですか?
私にこれを照らしてください。
ありがとうございます。