8
私はOpenLCLでアルゴリズムを書いていますが、かなりの量のデータを記憶する必要があります。long[70]とlong[200]かそれ以上のカーネルがあります。AMDデバイス上の物理メモリ:ローカル対プライベート
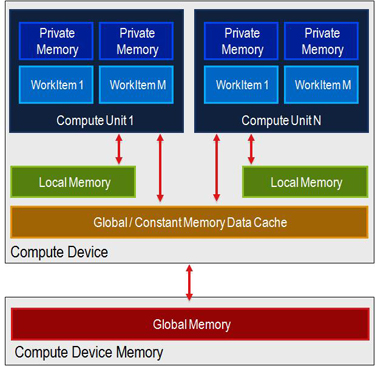
最近のAMDデバイスには32 KiB __localメモリがあります。これは、20〜58個の作業単位の情報を格納するのに十分な量です(カーネルあたりの所与のデータ量)。しかし、私がアーキテクチャから理解しているもの(特にthis drawing)から、各シェーダコアには専用メモリが専用に用意されています。私はしかし、そのサイズを見つけることに失敗します。
{kind=link}
各カーネルが持つプライベートメモリの量を知る方法を教えてもらえますか?
私は特にこれらのいくつかをすぐに購入する予定であるので、私はHD7970について特に興味があります。
編集:問題解決、答えは付録のhereあるD.
私は、プライベートメモリがコアごとに専用されているとは思っていません。演算子リソースごとのレジスタファイルにマップされています。各作業項目は、計算ユニットレジスタファイルから割り当てられたレジスタを取得します。必要な数は、任意の瞬間における飛行中の波面の数を決定します。 – talonmies
有名などこからでも見た図http://www.codeproject.com/KB/showcase/Memory-Spaces/image001.jpg私はプライベートメモリが__localメモリとは物理的に異なっていると結論付けました。 – user1111929
はい、物理的に異なります。プライベートメモリは、最新のAMDデバイスのユニットレベル共有メモリを計算するためのローカルメモリである計算ユニットレジスタファイルにマップされます。いくつかの初期のOpenCL互換GPUにはダイ共有メモリがなく、ローカルメモリは単なるSDRAMでした。コアごとではなく、ローカル・エフェクトのワークグループごとにワークアイテムごとにどれだけ使用するかは、計算単位ごとに実行される同時波面の数です。 – talonmies