10
NVIDIAはメモリ転送のオーバーヘッドを減らすためにGPUDirectを提供しています。私はAMD/ATIのための同様の概念があるかどうか疑問に思いますか?具体的には、AMDのOpenCLはCUDAのGPUDirectに似たものを提供していますか?
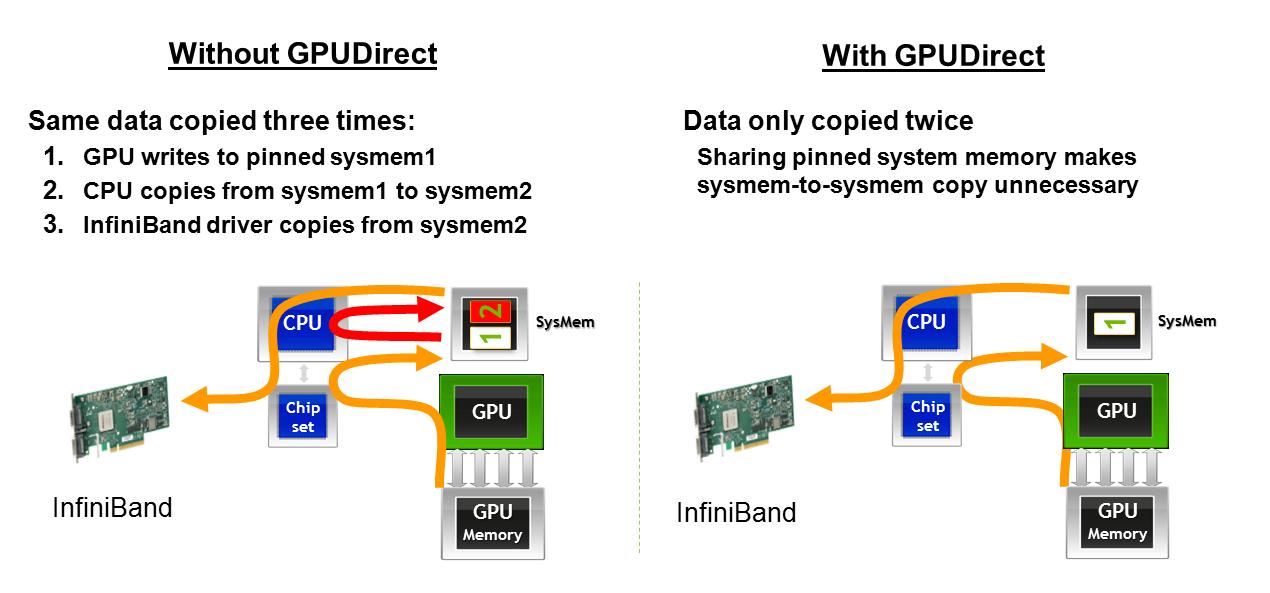
1)ネットワークカードとのインターフェイス時にAMD GPUが2回目のメモリ転送を行わないようにしてください(as described here)。グラフィックスがある時点で失われた場合、GPUダイレクトが1つのマシン上のGPUからのデータをネットワークインタフェースを介して転送する際の影響の説明を以下に示します。GPUDirectを使用すると、GPUメモリはホストメモリに移動し、インターフェイスカード。 GPUDirectがなければ、GPUメモリは1つのアドレス空間でホストメモリに送られ、CPUはコピーを行って別のホストメモリアドレス空間にメモリを取得しなければなりません。
{kind=link}
2)同じPCIeバス上で2つのGPUを共有する場合、AMD GPUはP2Pメモリ転送を許可しますか?as described here。 GPUDirectを使用すると、同じPCIeバス上のGPU間で、ホストメモリに触れることなく直接データを移動できます。 GPUDirectを使用しないと、データはGPUがどこにあるかにかかわらず、別のGPUに到達する前に必ずホストに戻る必要があります。
{kind=link}
編集:BTW、私はGPUDirectのどれが実際にどのくらいのものが実際にどれだけ有用であるかはわかりません。私は実際に何かのためにそれを使用してGPUのプログラマのことを聞いたことがない。これについての考えも大歓迎です。
は、リンクされたグラフィックスは後日ダウン取られた場合の二つの技術のテキスト記述を提供してもらえますか?また、私は2番目のグラフィックが何が提供されているか不明であることがわかります。 – James
ジェームズ、これが行われます。 – arrayfire
@gpu:mvapich2は、最近のリリースではGPUの直接サポートを持っています。私はこれを使っていますが、実際には速いです。 'MPI_Send'と' MPI_recv'を呼び出し、引数としてGPUメモリポインタを渡し、 – talonmies