説明
は望ましくない部分文字列は、電子メールアドレスに似ているが、便利jpgで終わります。したがって、否定的な先読みでは、ファイル拡張子を除外できます。
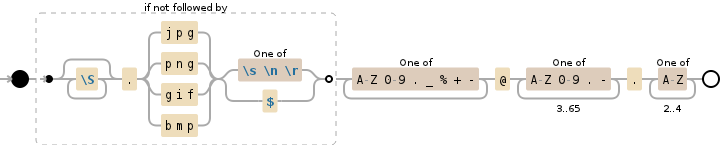
(?!\S*\.(?:jpg|png|gif|bmp)(?:[\s\n\r]|$))[A-Z0-9._%+-][email protected][A-Z0-9.-]{3,65}\.[A-Z]{2,4}
例
ライブデモ
https://regex101.com/r/mU7bO3/2
サンプルテキスト
[email protected] [email protected] [email protected]
サンプルは、使用している言語は何
[email protected]
[email protected]
説明
NODE EXPLANATION
----------------------------------------------------------------------
(?! look ahead to see if there is not:
----------------------------------------------------------------------
\S* non-whitespace (all but \n, \r, \t, \f,
and " ") (0 or more times (matching the
most amount possible))
----------------------------------------------------------------------
\. '.'
----------------------------------------------------------------------
(?: group, but do not capture:
----------------------------------------------------------------------
jpg 'jpg'
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
png 'png'
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
gif 'gif'
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
bmp 'bmp'
----------------------------------------------------------------------
) end of grouping
----------------------------------------------------------------------
(?: group, but do not capture:
----------------------------------------------------------------------
[\s\n\r] any character of: whitespace (\n, \r,
\t, \f, and " "), '\n' (newline), '\r'
(carriage return)
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
$ before an optional \n, and the end of
a "line"
----------------------------------------------------------------------
) end of grouping
----------------------------------------------------------------------
) end of look-ahead
----------------------------------------------------------------------
[A-Z0-9._%+-]+ any character of: 'A' to 'Z', '0' to '9',
'.', '_', '%', '+', '-' (1 or more times
(matching the most amount possible))
----------------------------------------------------------------------
@ '@'
----------------------------------------------------------------------
[A-Z0-9.-]{3,65} any character of: 'A' to 'Z', '0' to '9',
'.', '-' (between 3 and 65 times (matching
the most amount possible))
----------------------------------------------------------------------
\. '.'
----------------------------------------------------------------------
[A-Z]{2,4} any character of: 'A' to 'Z' (between 2
and 4 times (matching the most amount
possible))
----------------------------------------------------------------------
にマッチしますか? –
なぜTLDを4文字に制限していますか?参照してください:http://www.iana.org/domains/root/db – Toto
私は言語を知らない - それは正規表現に基づいてテキスト/ htmlファイルを検索するソフトウェア(他人によって書かれた)ですユーザーが変更することができます。明らかにデフォルトの正規表現は古くなっています - ありがとうToto。 – Melchester