1
コンテキスト、geditでの構文ハイライト大規模なマッチ内のグループを繰り返しキャプチャする正規表現ですか?
問題:特定の領域内のすべての出現をキャプチャしたい。玩具例:
私はkeyword1の
((text))以内(ハイライト)アル$ 0-9(一桁)の発生を、キャプチャしたい
other text here $5
keyword1 -> ((ran$3dom$6t:,ext$9 ))
keyword1 -> (( ran$2dom$4t:,ext$6))
other text here $7
。 (ここでは$3、$6、$9、$2、$4、$6しかしませ$5と$7)。これは次のようなものです:より大きな試合の中でグループを繰り返しキャプチャするにはどうすればいいですか?グループはで発生する可能性がある場所
は、私はすべてのテキストをつかむことができます。(?<=keyword1)|\(\(.*\)\)
<context id="keyword1" style-ref="argument">
<match>(?<=keyword1)|\(\(.*\)\)</match>
</context>
私はこの関連の質問を発見した(geditのは、デフォルトでは、\ Gを使用しています):How can I write a regex to repeatedly capture group within a larger match?が、その答えはルック内の無限の反復を使用していますその後ろは残念ながらgeditでサポートされていません(私が知る限り)。なにか提案を?あなただけのキーワードで始まる行に取り組んでいることを確認するには
 に似た行をキャプチャ
に似た行をキャプチャ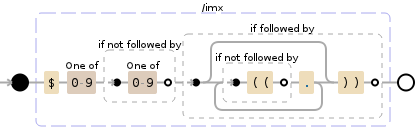
geditがPCREをサポートしている場合は、\ Gベースの正規表現を使用できます。 –