説明
(?<=\n|\A)(?:public\s)?(class|interface|enum)\s([^\n\s]*)
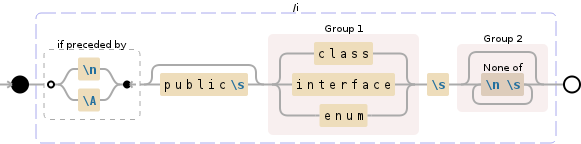
この正規表現は、次のん:
- 文字列が
classまたはinterfaceまたはenum こと
publicか
- を開始することができ
- キャプチャ名
注、私は例
ライブ例
https://regex101.com/r/vR0iK3/1
サンプルテキスト
をグローバルと大文字小文字を区別しないフラグ
を使用することをお勧めします /**
*
* @author XXXX
* Introduction: A common interface that judges all kinds of algorithm tags.
* some other comment
*/
public class TagMatchingInterface
{
// content
public class InnerClazz{
// content
}
}
サンプル
[0][0] = public class TagMatchingInterface
[0][1] = class
[0][2] = TagMatchingInterface
キャプチャグループマッチ:
- グループ0はマッチ全体
- グループ1クラス
- グループ2名
を取得し、取得します
説明
NODE EXPLANATION
----------------------------------------------------------------------
(?<= look behind to see if there is:
----------------------------------------------------------------------
\n '\n' (newline)
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
\A Start of the string
----------------------------------------------------------------------
) end of look-behind
----------------------------------------------------------------------
(?: group, but do not capture (optional
(matching the most amount possible)):
----------------------------------------------------------------------
public 'public'
----------------------------------------------------------------------
\s whitespace (\n, \r, \t, \f, and " ")
----------------------------------------------------------------------
)? end of grouping
----------------------------------------------------------------------
( group and capture to \1:
----------------------------------------------------------------------
class 'class'
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
interface 'interface'
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
enum 'enum'
----------------------------------------------------------------------
) end of \1
----------------------------------------------------------------------
\s whitespace (\n, \r, \t, \f, and " ")
----------------------------------------------------------------------
( group and capture to \2:
----------------------------------------------------------------------
[^\n\s]* any character except: '\n' (newline),
whitespace (\n, \r, \t, \f, and " ") (0
or more times (matching the most amount
possible))
----------------------------------------------------------------------
) end of \2
----------------------------------------------------------------------
なぜ気になるのですか?クラス名はファイル名の右に... – Laurel
*何らかの理由で* **何*理由***? Javaはコンパイルされた言語です。実行時には通常、ソースはありません。 –
MySQLからクラスをロードするために私のカスタムクラスロードを使いたいので、コンテンツを複数行の文字列としてスキャンする必要があります –