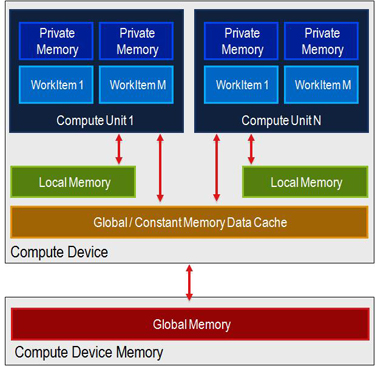
OpenCLは実際にメモリのキャッシュについては説明しません。最新のグラフィックスカードには、グローバルメモリのためのいくつかの種類のキャッシュプロトコルがありますが、古いカードでは保証されていません。しかし、ここでは異なる記憶の概要があります。
プライベートメモリ - このメモリは、作業項目ごとのレジスタとして保持されます。 GPUには計算ユニットごとに非常に大きなレジスタファイルがあります。しかし、このメモリは必要に応じてローカルメモリに流出する可能性があります。プライベートメモリは、変数を作成するときにデフォルトで割り当てられます。
ローカルメモリ - ワークグループにローカルであり、ワークグループによって共有されるメモリ。このメモリシステムは、通常、計算ユニット自体にあり、他のワークグループによって読み書きすることはできません。このメモリは、通常、GPUアーキテクチャ(CPUアーキテクチャ上では、このメモリはシステムメモリの一部に過ぎません)でのレイテンシが非常に短くなっています。このメモリは、通常、グローバルメモリの手動キャッシュとして使用されます。ローカルメモリは__local属性で指定します。
定数メモリ - グローバルメモリの一部ですが、読み取り専用であるため、積極的にキャッシュすることができます。 __constantは、このタイプのメモリを定義するために使用されます。
グローバルメモリ - これはGPUのメインメモリです。 __globalは、メモリをグローバルメモリ空間に配置するために使用されます。
{kind=link}
私はそれを感謝します。グローバルメモリの50%のプライベート/ローカルメモリを割り当てることができますか? ...現代GPUで – Maiss
@Maiss:現代GPUのローカルメモリは、計算単位あたり16kBから64kBの間のどこかにあります(そして、グローバルメモリafaikに流出しません)。 – Grizzly
プライベートメモリがオフチップDRAMである可能性があるというさまざまな情報を読んだことがありますが、これは最も遅くなりますが、最近のGPUはこのメモリをmem階層の最高のレジスタ/ L1にキャッシュします。誰かがこれを確認できますか?プライベートmemの性質を判断する方法はありますか?最も遅い(オフチップ)、または最速の(レジスタ)かもしれないようです。 – JDS