0
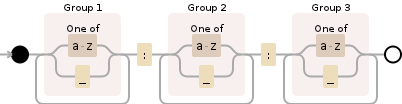
こんにちは、それぞれの式をコロンから区切ります。だから、 'ss_vv'、 'kk'、 'pp'を取得したい。しかし、以下の2つの印刷表現は私に 'v'と 'k'を与え、各文字列の部分だけを取得します。誰がここで何が間違って見ることができますかPythonの正規表現とグループ関数
m0 = re.compile(r'([a-z]|_)+:([a-z]|_)+:([a-z]|_)+')
m1 = m0.search('ss_vv:kk:pp')
print m1.group(1)
print m1.group(2)

':'の単純な分割? – Jan