2
SMILESの標準化学式文字列をトークン化するパーサであるhttp:// frowns.sourceforge.netから入手可能なfrownsパーサを使用して遊んでいます。特に私はそれをRustに移植しようとしています。Rust正規表現のキャプチャフィールドを反復する
パーサーで「原子」トークンの元の正規表現は、この(パイソン)のように見える:フィールドリストは、正規表現パーサーのreportability、ならびにトラック解析エラーを改善するために使用される
element_symbols_pattern = \
r"C[laroudsemf]?|Os?|N[eaibdpos]?|S[icernbmg]?|P[drmtboau]?|" \
r"H[eofgas]?|c|n|o|s|p|A[lrsgutcm]|B[eraik]?|Dy|E[urs]|F[erm]?|" \
r"G[aed]|I[nr]?|Kr?|L[iaur]|M[gnodt]|R[buhenaf]|T[icebmalh]|" \
r"U|V|W|Xe|Yb?|Z[nr]|\*"
atom_fields = [
"raw_atom",
"open_bracket",
"weight",
"element",
"chiral_count",
"chiral_named",
"chiral_symbols",
"hcount",
"positive_count",
"positive_symbols",
"negative_count",
"negative_symbols",
"error_1",
"error_2",
"close_bracket",
"error_3",
]
atom = re.compile(r"""
(?P<raw_atom>Cl|Br|[cnospBCNOFPSI]) | # "raw" means outside of brackets
(
(?P<open_bracket>\[) # Start bracket
(?P<weight>\d+)? # Atomic weight (optional)
( # valid term or error
( # valid term
(?P<element>""" + element_symbols_pattern + r""") # element or aromatic
( # Chirality can be
(?P<chiral_count>@\d+) | # @1 @2 @3 ...
(?P<chiral_named> # or
@TH[12] | # @TA1 @TA2
@AL[12] | # @AL1 @AL2
@SP[123] | # @SP1 @SP2 @SP3
@TB(1[0-9]?|20?|[3-9]) | # @TB{1-20}
@OH(1[0-9]?|2[0-9]?|30?|[4-9])) | # @OH{1-30}
(?P<chiral_symbols>@+) # or @@@@@@@...
)? # and chirality is optional
(?P<hcount>H\d*)? # Optional hydrogen count
( # Charges can be
(?P<positive_count>\+\d+) | # +<number>
(?P<positive_symbols>\++) | # +++... This includes the single '+'
(?P<negative_count>-\d+) | # -<number>
(?P<negative_symbols>-+) # ---... including a single '-'
)? # and are optional
(?P<error_1>[^\]]+)? # If there's anything left, it's an error
) | ( # End of parsing stuff in []s, except
(?P<error_2>[^\]]*) # If there was an error, we get here
))
((?P<close_bracket>\])| # End bracket
(?P<error_3>$)) # unexpectedly reached end of string
)
""", re.X)
。
括弧を付けずにトークンを正しく解析しましたが、角括弧(例えば、[S]の代わりにS)を含めると、それが壊れてしまいます。だから私は、コメントでそれを絞り込むました:
extern crate regex;
use regex::Regex;
fn main() {
let atom_fields: Vec<&'static str> = vec![
"raw_atom",
"open_bracket",
"weight",
"element",
"chiral_count",
"chiral_named",
"chiral_symbols",
"hcount",
"positive_count",
"positive_symbols",
"negative_count",
"negative_symbols",
"error_1",
"error_2",
"close_bracket",
"error_3"
];
const EL_SYMBOLS: &'static str = r#"(?P<element>S?|\*")"#;
let atom_re_str: &String = &String::from(vec![
// r"(?P<raw_atom>Cl|Br|[cnospBCNOFPSI])|", // "raw" means outside of brackets
r"(",
r"(?P<open_bracket>\[)", // Start bracket
// r"(?P<weight>\d+)?", // Atomic weight (optional)
r"(", // valid term or error
r"(", // valid term
&EL_SYMBOLS, // element or aromatic
// r"(", // Chirality can be
// r"(?P<chiral_count>@\d+)|", // @1 @2 @3 ...
// r"(?P<chiral_named>", // or
// r"@TH[12]|", // @TA1 @TA2
// r"@AL[12]|", // @AL1 @AL2
// r"@SP[123]|", // @SP1 @SP2 @SP3
// r"@TB(1[0-9]?|20?|[3-9])|", // @TB{1-20}
// r"@OH(1[0-9]?|2[0-9]?|30?|[4-9]))|", // @OH{1-30}
// r"(?P<chiral_symbols>@+)", // or @@@@....,
// r")?", // and chirality is optional
// r"(?P<hcount>H\d*)?", // Optional hydrogen count
// r"(", // Charges can be
// r"(?P<positive_count>\+\d+)|", // +<number>
// r"(?P<positive_symbols>\++)|", // +++...including a single '+'
// r"(?P<negative_count>-\d+)|", // -<number>
// r"(?P<negative_symbols>-+)", // ---... including a single '-'
// r")?", // and are optional
// r"(?P<error_1>[^\]]+)?", // anything left is an error
r")", // End of stuff in []s, except
r"|((?P<error_2>[^\]]*)", // If other error, we get here
r"))",
r"((?P<close_bracket>\])|", // End bracket
r"(?P<error_3>$)))"].join("")); // unexpected end of string
println!("generated regex: {}", &atom_re_str);
let atom_re = Regex::new(&atom_re_str).unwrap();
for cur_char in "[S]".chars() {
let cur_string = cur_char.to_string();
println!("cur string: {}", &cur_string);
let captures = atom_re.captures(&cur_string.as_str()).unwrap();
// if captures.name("atom").is_some() {
// for cur_field in &atom_fields {
// let field_capture = captures.name(cur_field);
// if cur_field.contains("error") {
// if *cur_field == "error_3" {
// // TODO replace me with a real error
// println!("current char: {:?}", &cur_char);
// panic!("Missing a close bracket (]). Looks like: {}.",
// field_capture.unwrap());
// } else {
// panic!("I don't recognize the character. Looks like: {}.",
// field_capture.unwrap());
// }
// } else {
// println!("ok! matched {:?}", &cur_char);
// }
// }
// }
}
}
-
をあなたが生成錆の正規表現がDebuggexに動作することを確認できます
((?P<open_bracket>\[)(((?P<element>S?|\*"))|((?P<error_2>[^\]]*)))((?P<close_bracket>\])|(?P<error_3>$)))
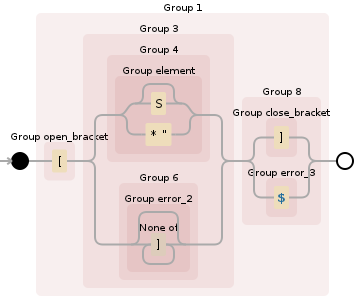
(http://debuggex.com/r/7j75Y2F1ph1v9jfL)
例を実行すると(https://gitlab.com/araster/frowns_regex)、開いている括弧は正しく解析されますが、.captures().unwrap()は次の文字 'S'で消滅します。私が完全な式を使用すると、角括弧を持たない限り、眉毛のテストファイルからあらゆる種類のものを解析できます。
私は間違っていますか?
Downvoter:この質問を改善するためにできることはありますか? –
(a)質問にはあまり関係ないコードがたくさんあります。 [mcve](http://stackoverflow.com/help/mcve)が最適かもしれませんが、ここでは実際には可能ではないかもしれません。 (b)多くのリンクを整形することができます。 (c)SOが特定のリンクの使用を禁止している理由(たとえば、リンクが簡単に無効になる可能性があるため)があります。そのリンクで何が間違っているのかを見つけ出し、これを解決することは価値があります(たとえば、イメージを再ホストするなど)。 ---あなたがそれほど新しいことを見たことがない、そうでなければ、私は前に私のdownvoteを説明していただろう、申し訳ありません!しかし:歓迎:) –