9
hashmapはどのように内部実装されていますか?私はどこかリンク先リストを使用していますが、いくつかの場所では配列として記述されています。hashmapは内部でリンクリストまたは配列を使用してjavaで実装されています
私はHashSetのためのコードを勉強しようとした項目配列を見つけ、LinkedListのは
hashmapはどのように内部実装されていますか?私はどこかリンク先リストを使用していますが、いくつかの場所では配列として記述されています。hashmapは内部でリンクリストまたは配列を使用してjavaで実装されています
私はHashSetのためのコードを勉強しようとした項目配列を見つけ、LinkedListのは
を使用する場合、それは基本的に次のようになります。だから、あなたは、各インデックスは、いくつかに該当する主な配列を持っている
this is the main array
↓
[Entry] → Entry → Entry ← here is the linked-list
[Entry]
[Entry] → Entry
[Entry]
[null ]
[null ]
ハッシュ値(配列のサイズに対してmod 'ed *)。
次に、それぞれ同じハッシュ値(mod 'ed *)を持つ次のエントリを指します。これはリンクされたリストが入っている場所です。
*:テクニカルノートでは、modの前にit's first hashed with a different functionが編集されていますが、基本的な実装では、改造だけで動作します。
Java 8以降、バケット内のLinkedListは大きすぎるとTreeMapで置き換えることができます。こちらをご覧ください:http://www.nurkiewicz.com/2014/04/hashmap-performance-improvements-in.html – RobAu
ハッシュマップのエントリは「バケット」に格納されます。各ハッシュマップには配列があり、その配列にキーのハッシュコード(例:position = hashcode%arraysize)に従ってエントリが配置されます。
複数のエントリが同じバケットで終わる場合、それらのエントリはリンクリスト(Dukelingsの回答も参照)に格納されます。したがって、bucket-metaphor:各配列エントリは、すべての一致するキーをダンプする "バケット"です。
このリストのランダムな位置にアクセスする必要があるため、派生した「一定時間」の動作を得るには、バケットの配列を使用する必要があります。バケット内では、必要なキーが見つかるまですべての要素をトラバースする必要がありますので、リンクリストを追加する方が簡単です(サイズを変更する必要はありません)。
これは良いキーのハッシュ関数の必要性を示しています。すべてのキーが少数の値にハッシュされると、長いリンクリストが検索され、多くの(高速にアクセスできる)空のバケットが得られるからです。
のHashMapはHashMap.Entryオブジェクトの配列を持っています
/**
* The table, resized as necessary. Length MUST Always be a power of two.
*/
transient Entry<K,V>[] table;
私たちは、エントリが(例えばHashMap.Entry結合が「バケット」と呼ばれている)片方向リンクリストですが、それは実際にはないと言うことができますjava.util.LinkedList
自分自身を参照してください:
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
public final int hashCode() {
return (key==null ? 0 : key.hashCode())^
(value==null ? 0 : value.hashCode());
}
public final String toString() {
return getKey() + "=" + getValue();
}
/**
* This method is invoked whenever the value in an entry is
* overwritten by an invocation of put(k,v) for a key k that's already
* in the HashMap.
*/
void recordAccess(HashMap<K,V> m) {
}
/**
* This method is invoked whenever the entry is
* removed from the table.
*/
void recordRemoval(HashMap<K,V> m) {
}
}
のHashMapは内部でキーと値のペアを格納するためのエントリを使用しています。エントリはLinkedList型です。
エントリには、次が含ま - >
Kキー、
V値とバケットの位置に
エントリ次>すなわち次のエントリ。
static class Entry<K, V> {
K key;
V value;
Entry<K,V> next;
public Entry(K key, V value, Entry<K,V> next){
this.key = key;
this.value = value;
this.next = next;
}
}
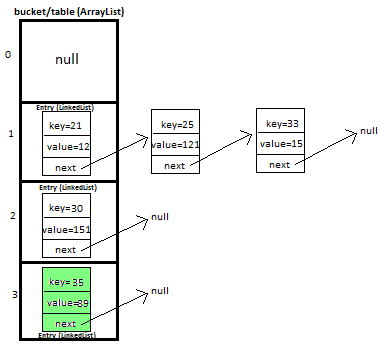
HashMapの図 -
から:http://www.javamadesoeasy.com/2015/02/hashmap-custom-implementation.html
あなたは 'HashMap'の実装について学びたいと思ったときに、なぜあなたはHashSet''を見たのですか? 'HashMap'はリンクリストを使用しますが、' LinkedList'クラスは使用しません。 –
ソースコードを読んでください?それは実際に有益なコメントがいっぱいです... – vikingsteve
@SotiriosDelimanolisハッシュマップと一緒にハッシュセットを学ぶことは、すべてのコレクションの内部実装をちょうど行っていると思います。 – dexterousashish