-1
[value]と一致する2つの正規表現と、html属性に一致する別の正規表現があるが、それらを1つの正規表現に結合する必要がある。PHP preg_replaceはhtmlで一致を見つけるが、html属性でない場合
これは私が[value]
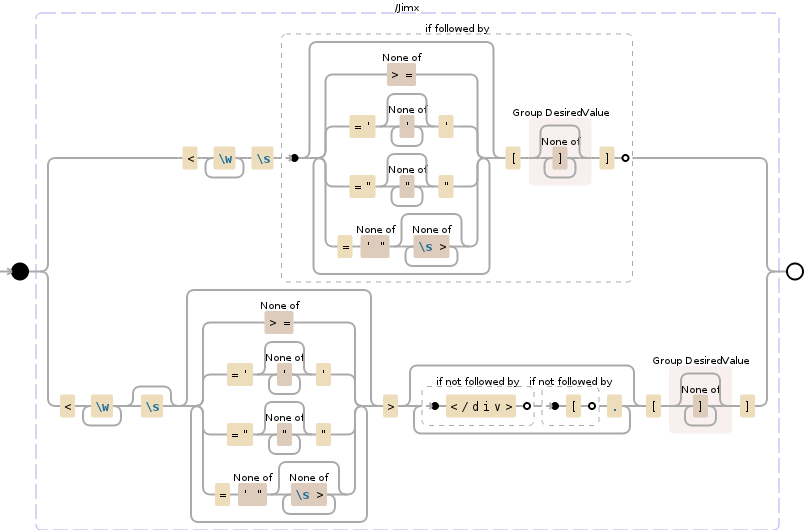
$tagregexp = '[a-zA-Z_\-][0-9a-zA-Z_\-\+]{2,}';
$pattern =
'\\[' // Opening bracket
. '(\\[?)' // 1: Optional second opening bracket for escaping shortcodes: [[tag]]
. "($tagregexp)" // 2: Shortcode name
. '(?![\\w-])' // Not followed by word character or hyphen
. '(' // 3: Unroll the loop: Inside the opening shortcode tag
. '[^\\]\\/]*' // Not a closing bracket or forward slash
. '(?:'
. '\\/(?!\\])' // A forward slash not followed by a closing bracket
. '[^\\]\\/]*' // Not a closing bracket or forward slash
. ')*?'
. ')'
. '(?:'
. '(\\/)' // 4: Self closing tag ...
. '\\]' // ... and closing bracket
. '|'
. '\\]' // Closing bracket
. '(?:'
. '(' // 5: Unroll the loop: Optionally, anything between the opening and closing shortcode tags
. '[^\\[]*+' // Not an opening bracket
. '(?:'
. '\\[(?!\\/\\2\\])' // An opening bracket not followed by the closing shortcode tag
. '[^\\[]*+' // Not an opening bracket
. ')*+'
. ')'
. '\\[\\/\\2\\]' // Closing shortcode tag
. ')?'
. ')'
. '(\\]?)'; // 6: Optional second closing bracket for escaping shortcodes: [[tag]]
属性と値が一致する(\S+)=["']?((?:.(?!["']?\s+(?:\S+)=|[>"']))+.)["']?この正規表現を検索して働いている正規表現です。 example here
私は、次の例
<div [value] ></div><div>[value]</div>
しかし
- この例では、一致を見つけることができませんで
[value]にマッチする正規表現をしたいと思います
はちょうどあなたが定期的にhtmlコードを解析しようとしているように見える表面には、私のpreg_replace_callback
preg_replace_callback($pattern, replace_matches, $html);
は、あなたがこのためにパーサを使用することを検討していますか? – chris85
これはPHP文字列であり、Java文字列ではありません。すべてを二重にエスケープする必要はありません。連結を使用する代わりに、x修飾子を使用してください(もしあなたがnowdoc文字列を使用できる場合)。 html(またはxml)を扱いたい場合は、正規表現を忘れてDOMDocument(そして最終的にDOMXPath)を使います。 –
他のもの、閉じる角括弧は特殊文字ではありません、あなたはそれをエスケープする必要はありません。文字クラスの中の角括弧は何も特別なものはありません。 '[^ \] []の代わりに' [^ [] 'と書くことができます。 *([^]] 'と' []] 'を書くことさえできます。なぜなら、最初の位置では閉じた角括弧がリテラル文字として見えるからです。)* –